.png)
A Pandas DataFrame is a 2 dimensional data structure, like a 2 dimensional Heterogeneous data array, or a table with rows and columns.
Features of DataFrame
Potentially columns are of different types
Size – Mutable
Labeled axes (rows and columns)
Can Perform Arithmetic operations on rows and columns
Create DataFrame A pandas DataFrame can be created using various inputs like −
Lists
dict
Series
Numpy ndarrays
Another DataFrame
Create an Empty DataFrame A basic DataFrame, which can be created is an Empty Dataframe.
Example
import pandas as pd
df = pd.DataFrame()
print (df)

Create a DataFrame from Lists The DataFrame can be created using a single list or a list of lists.
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print(df)

import pandas as pd
data = [['Rohit',10],['Ram',12],['Sumit',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print (df)

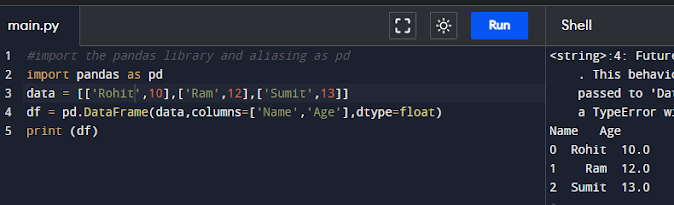
import pandas as pd
data = [['Rohit',10],['Ram',12],['Sumit',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print (df)
Create a DataFrame from Dict of Lists All the ndarrays must be of same length. If index is passed, then the length of the index should equal to the length of the arrays. If no index is passed, then by default, index will be range(n), where n is the array length.
import pandas as pd
data = {'Name':['Rohit', 'Rajat', 'Pankaj','Rocky'],'Age':[28,34, 29,42]}
df = pd.DataFrame(data)
print (df)

Create a DataFrame from List of Dicts List of Dictionaries can be passed as input data to create a DataFrame. The dictionary keys are by default taken as column names.
import pandas as pd
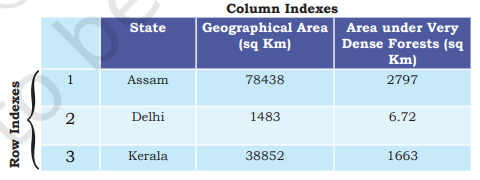
dictForest = {'State': ['Assam', 'Delhi','Kerala'],'GArea': [78438, 1483, 38852] ,
'VDF' : [2797, 6.72,1663]}
dFrameForest= pd.DataFrame(dictForest)
print(dFrameForest)

import pandas as pd
dictForest = {'State': ['Assam', 'Delhi','Kerala'],'GArea': [78438, 1483, 38852] ,
'VDF' : [2797, 6.72,1663]}
dFrameForest=pd.DataFrame(dictForest,columns = ['State','VDF', 'GArea'])
print(dFrameForest)

Creation of DataFrame from Series
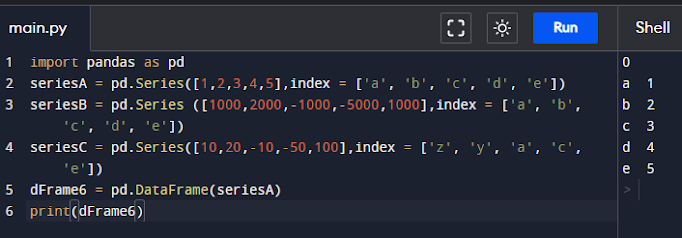
import pandas as pd
seriesA = pd.Series([1,2,3,4,5],index = ['a', 'b', 'c', 'd', 'e'])
seriesB = pd.Series ([1000,2000,-1000,-5000,1000],index = ['a', 'b', 'c', 'd', 'e'])
seriesC = pd.Series([10,20,-10,-50,100],index = ['z', 'y', 'a', 'c', 'e'])
dFrame6 = pd.DataFrame(seriesA)
print(dFrame6)
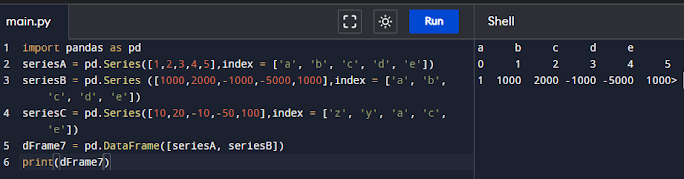
import pandas as pd
seriesA = pd.Series([1,2,3,4,5],index = ['a', 'b', 'c', 'd', 'e'])
seriesB = pd.Series ([1000,2000,-1000,-5000,1000],index = ['a', 'b', 'c', 'd', 'e'])
seriesC = pd.Series([10,20,-10,-50,100],index = ['z', 'y', 'a', 'c', 'e'])
dFrame7 = pd.DataFrame([seriesA, seriesB])
print(dFrame7)
Creation of DataFrame from Dictionary of Series
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
Operations on rows and columns in DataFrames
We can perform some basic operations on rows and columns of a DataFrame like selection, deletion, addition, and renaming, as discussed in this section.
Adding a New Column to a DataFrame We can easily add a new column to a DataFrame. Let us consider the DataFrame ResultDF defined earlier. In order to add a new column for another student ‘Preeti’, we can write the following statement:
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91,97],index=['Maths','Science','Hindi'])
,'Ramit': pd.Series([92, 81,96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91,88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
ResultDF['Preeti']=[89,78,76]
print(ResultDF)

Assigning values to a new column label that does not exist will create a new column at the end. If the column already exists in the DataFrame then the assignment statement will update the values of the already existing column, for example:
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
ResultDF['Preeti']=[89,78,76]
ResultDF['Ramit']=[99, 98, 78]
print(ResultDF)

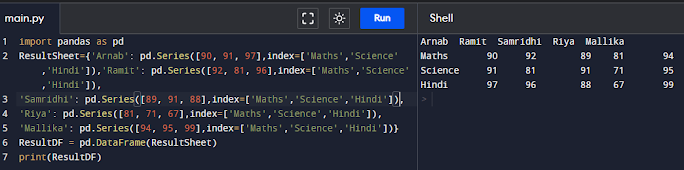
Adding a New Row to a DataFrame We can add a new row to a DataFrame using the DataFrame.loc[ ] method.
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
ResultDF.loc['English'] = [85, 86, 83, 80, 90]
print(ResultDF)

We cannot use this method to add a row of data with already existing (duplicate) index value (label). In such case, a row with this index label will be updated, for example:
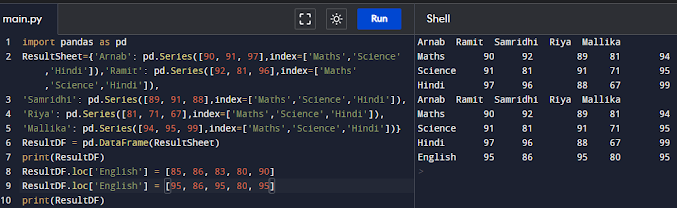
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
ResultDF.loc['English'] = [85, 86, 83, 80, 90]
ResultDF.loc['English'] = [95, 86, 95, 80, 95]
print(ResultDF)
DataFRame.loc[] method can also be used to change the data values of a row to a particular value. For example, the following statement sets marks in 'Maths' for all columns to 0:
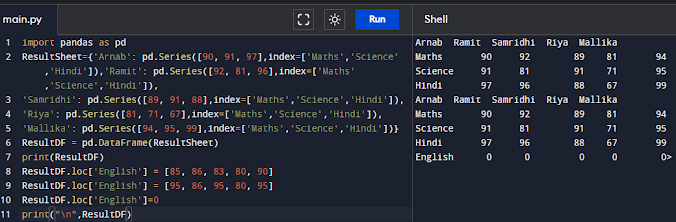
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF)
ResultDF.loc['English'] = [85, 86, 83, 80, 90]
ResultDF.loc['English'] = [95, 86, 95, 80, 95]
print(ResultDF)
ResultDF.loc['English'] = [0]
print(ResultDF)
we can set all values of a DataFrame to a particular value, for example:

import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
ResultDF[:]=0
print(ResultDF,"\n")
Deleting Rows or Columns from a DataFrame We can use the DataFrame.drop() method.
We need to specify the names of the labels to be dropped and the axis from which they need to be dropped.
To delete a row, the parameter axis is assigned the value 0
To deleting a column,the parameter axis is assigned the value 1
Let’s take an example to better understanding.
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
# to drop a perticular Row
ResultDF = ResultDF.drop('Science', axis=0)
print(ResultDF,"\n")

You can also delete multiple Rows
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
# to drop a perticular Row
ResultDF = ResultDF.drop(['Science','Hindi'], axis=0)
print(ResultDF,"\n")

To delete Columns from DataFrame
import pandas as pd
ResultSheet={'Arnab': pd.Series([90,91,97],index=['Maths','Science','Hindi']),'Ramit' :pd.Series([92,81,96],index=['Maths','Science','Hindi']),'Samridhi':pd.Series([89,91,88],index=['Maths','Science','Hindi']),'Riya :pd.Series([81,71,67],index=['Maths','Science','Hindi']),'Mallika' : pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
# to drop Columns
ResultDF = ResultDF.drop(['Samridhi','Riya'], axis=1)
print(ResultDF,"\n")

Renaming Row Labels of a DataFrame We can change the labels of rows and columns in a DataFrame using the DataFrame.rename() method.The parameter axis='index' implies we want to change the index labels
import pandas as pd
ResultSheet={'Arnab': pd.Series([90,91,97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),'Samridhi': pd.Series([89,91, 88],index=['Maths','Science','Hindi']),'Riya': pd.Series([81,71,67],index=['Maths','Science','Hindi']),'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
ResultDF=ResultDF.rename({'Maths':'Sub1','Science':'Sub2','English':'Sub3',
'Hindi':'Sub4'}, axis='index')
print(ResultDF,"\n")
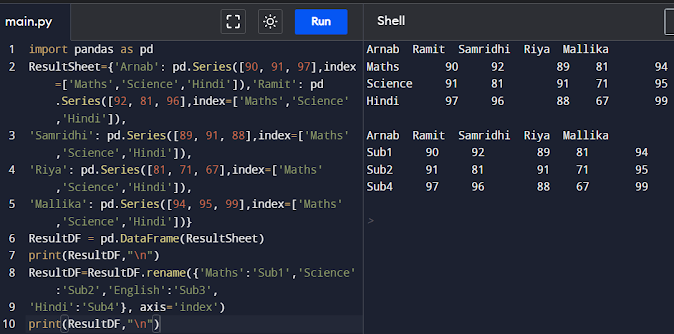
If no new label is passed corresponding to an existing label, the existing row label is left as it is
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
ResultDF=ResultDF.rename({'Maths':'Sub1','Science':'Sub2','English':'Sub3'}, axis='index')
print(ResultDF,"\n")
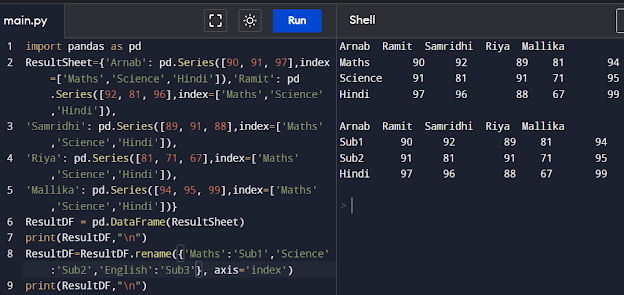
Renaming Column Labels of a DataFrame To alter the column names of ResultDF we can again use the rename() method, as shown below. The parameter axis='columns' implies we want to change the column labels:
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
ResultDF=ResultDF.rename({'Arnab':'Student','Ramit':'Student2','Samridhi':'Student3','Mallika':'Student4'},axis='columns')
print(ResultDF,"\n")
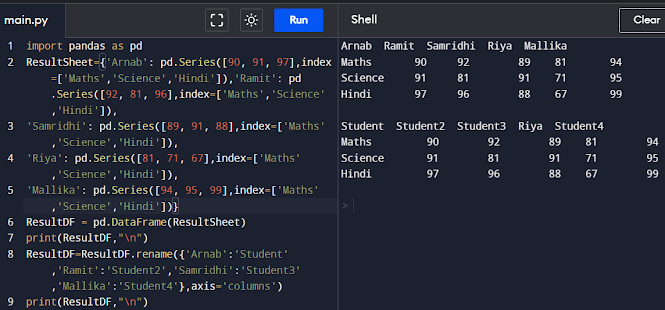
Accessing DataFrames Element through Indexing Data elements in a DataFrame can be accessed using indexing.There are two ways of indexing Dataframes : Label based indexing and Boolean Indexing.
Label Based Indexing :
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
print(ResultDF.loc['Science'],"\n")
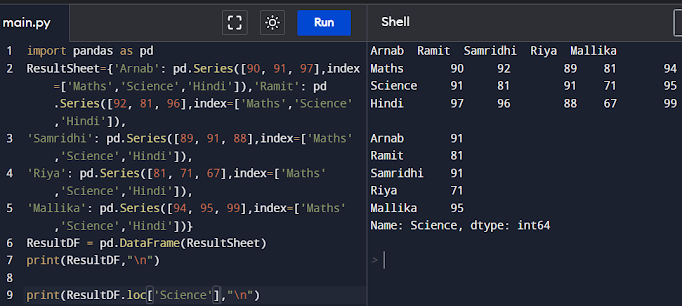
Accessing the column of the DataFrame
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
print(ResultDF.loc['Science'],"\n")
print(ResultDF.loc[:,'Arnab'],"\n")
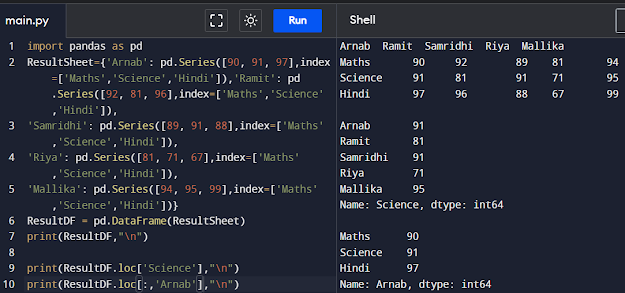
To read more than one row from a DataFrame, a list of row labels is used as shown below. Note that using [[]] returns a DataFrame.
Example print(ResultDF.loc[['Science'],[‘Hindi’]])
Boolean Indexing Boolean means a binary variable that can represent either of the two states - True (indicated by 1) or False (indicated by 0).
import pandas as pd
ResultSheet={'Arnab': pd.Series([90,91,97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92,81,96],index=['Maths','Science','Hindi']),'Samridhi': pd.Series([89,91,88],index=['Maths','Science','Hindi']),'Riya': pd.Series([81,71,67],index=['Maths','Science','Hindi']),'Mallika': pd.Series([94,95,99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
print(ResultDF.loc['Maths'] > 90)

Accessing DataFrames Element through Slicing :
Dataframe_object.loc[Start_row:End_row,start_columns:end_columns]
import pandas as pd
ResultSheet={'Arnab': pd.Series([90,91,97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92,81,96],index=['Maths','Science','Hindi']),'Samridhi': pd.Series([89,91,88],index=['Maths','Science','Hindi']),'Riya': pd.Series([81,71,67],index=['Maths','Science','Hindi']),'Mallika': pd.Series([94,95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
print(ResultDF.loc['Maths': 'Hindi'])

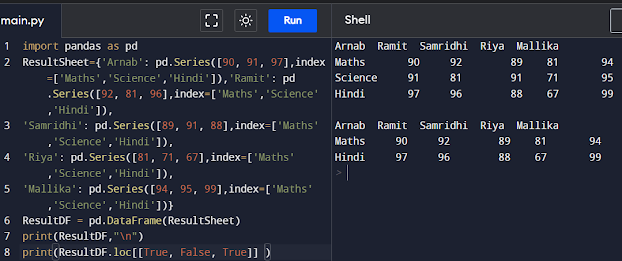
In order to select or omit particular row(s), we can use a Boolean list specifying ‘True’ for the rows to be shown and ‘False’ for the ones to be omitted in the output.
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
print(ResultDF.loc[[True, False, True]] )
Attributes of DataFrames Like Series, we can access certain properties called attributes of a DataFrame by using that property with the DataFrame name.


Importing and Exporting Data between CSV Files and DataFrames
We can create a DataFrame by importing data from CSV files where values are separated by commas. Similarly, we can also store or export data in a DataFrame as a .csv file.
You are suggested to create this csv file using a spreadsheet and save in your computer.
RollNo Name Eco Maths
1 Arnab 18 57
2 Kritika 23 45
3 Divyam 51 37
4 Vivaan 40 60
5 Aaroosh 18 27
And save as file_name.csv extension.
import pandas as pd
marks = pd.read_csv("CSV File path",sep =",", header=0)
print(marks)
CSV File path The first parameter to the read_csv() is the name of the comma separated data file along with its path.
sep ="," The parameter sep specifies whether the values are separated by comma, semicolon, tab, or any other character. The default value for sep is a space.
header=0 The parameter header specifies the number of the row whose values are to be used as the column names. It also marks the start of the data to be fetched. header=0 implies that column names are inferred from the first line of the file. By default, header=0.
We can exclusively specify column names using the parameter names while creating the DataFrame using the read_csv() function.
import pandas as pd
marks1 = pd.read_csv("CSV File Path",sep=",",names=['RNo','StudentName', 'Sub1', 'Sub2'])
print(marks1)
Exporting a DataFrame to a CSV file We can use the to_csv() function to save a DataFrame to a text or csv file.
import pandas as pd
ResultSheet={'Arnab': pd.Series([90, 91, 97],index=['Maths','Science','Hindi']),'Ramit': pd.Series([92, 81, 96],index=['Maths','Science','Hindi']),
'Samridhi': pd.Series([89, 91, 88],index=['Maths','Science','Hindi']),
'Riya': pd.Series([81, 71, 67],index=['Maths','Science','Hindi']),
'Mallika': pd.Series([94, 95, 99],index=['Maths','Science','Hindi'])}
ResultDF = pd.DataFrame(ResultSheet)
print(ResultDF,"\n")
ResultDF.to_csv(path_or_buf='Path where we want to save file', sep=',')
ResultDF.to_csv( 'Path where we want to save file', sep = '@', header = False, index= False)
